How to: Recon and Content Discovery

Intro
Recon plays a major role while hacking on a program. Recon doesn’t always mean to find subdomains belonging to a company, it also could relate to finding out how a company is setting up its properties and what resources they are using. Throughout this blogpost we will talk about different methods that may help us discover subdomains, internal resources, patterns used by a company, secret/private keys, API endpoints, and file/directory structures by combining different tools and resources. Doing a proper recon increases our attack surface and gives us a bigger scope to hack on in order to find more security vulnerabilities.
Brute Forcing For Subdomains
Traditionally, most hackers use tools such as Sublist3r, knockpy, or enumall by providing a word list and the target domain. This may work for most cases; however, I believe like anything else, this can be tweaked to be used to its fullest extent. Once we run our initial brute force and have identified how a company is setting up their subdomains, the next step should always be set to recursively brute force the different environments used by that company. For example, if a company uses `dashboard.dev.hackme.tld`, we should use this pattern to find more subdomains behind the `dev` environment. This will also allow us to identify other properties that may have less limitations than the actually production site.
This trick could also work by enumerating the company’s internal assets if they are placed behind a corporate or internal subdomain (for example, tools.corp.hackme.tld or tools.internal.hackme.tld). By brute forcing the corp/internal.hacketwo.com domain, we are able enumerate more properties in order to extend our attack surface.
Github
Github could be a great tool to gather information about a target’s infrastructure. We can simply search for a company name or website (like hackme.tld) to see the types of files and documents have been pushed to Github as a first step. We can also narrow down the search by using the information in our initial search to find more specific patterns. For example if we search for “hackme.tld” and find out that they are using “us.hackme.tld” for their internal apps like JIRA or their corporate VPN, that’s a good place to switch our focus to “us.hackme.tld” as our next search while we also do a subdomain brute force for anything behind “us.hackme.tld”.
Github is also a great place to look for credentials and private API keys. The hardest thing about this method is getting creative when it comes down to looking for different keys. Here’s a list of a few items I look for on github:
“Hackme.tld” API_key
“Hackme.tld” secret_key
“Hackme.tld” aws_key
“Hackme.tld” Password
“Hackme.tld” FTP
“Hackme.tld” login
“Hackme.tld” github_token
We can also find more information and endpoints on a subdomain by searching for it on Github as well. I have been able to find older API endpoints on github by just looking for “api.hackme.tld” and analyzing files that were submitted from a few years back. There are a ton of tools you can use to automate this work to save time, most of the time I personally like to do this manually because by reviewing files that may have the keywords above, we may find other “juicy” information even if the content that came up via those keywords were useless.
While looking around on Github may seem like a good idea, a few things may go wrong:
We may end up out of scope due to stumbling upon a third party app, or properties that simply are not in scope of the program.
We may find really old keys that no longer work or belong to the company.
The keys may also be fake and placed on Github purposely.
It's always a good idea to double check what you find to see if it's in scope.
Amazon Web Services
AWS has become a huge asset to thousands of different companies. Some companies just use AWS s3 buckets to host their content, while others use it to deploy and host their application. Like any other resource, AWS could also be misconfigured or abused by criminals. For example, it's often possible to find misconfigured s3 buckets that allow a user outside of the organization to read and write files on a bucket belonging to that company.
These properties can be discovered by combining a few different methods:
Using a google dork to find them: site:s3.amazonaws.com + hackme.tld
We can look them up on github: “hackme.tld” + “s3”
We can bruteforce AWS to find specific s3 buckets and automate this to speed it up
Lazys3 was developed based on method #3. This tool uses a list of commonly known s3 buckets, creates different patterns and permutations, grabs the response header, and returns them as long as it’s not returning 404. For example, if we are searching for s3 buckets under hackme.tld, this tool will run a test for each item of the wordlist, look up different patterns (i.e.: attachments-dev.hackme.tld, attachments.dev.hackme.tld, attachmentsdev.hackme.tld, and so on) and return those that have a response code of 200 or 403.
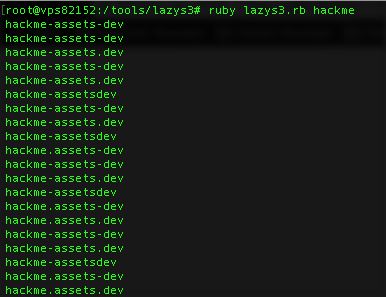
* Example patterns using lazys3 to look for a bucket named “assets” within the dev environment. The current version only outputs existing buckets.
While brute forcing and looking for different applications on Amazon Web Services may be help expand our attack surface, a few things could go wrong here as well:
The s3 bucket may hint that it belongs to a certain company, but in reality it’s not owned or operated by that company.
We may fall out of scope again due to different reasons including third party apps.
The s3 bucket may have read access, but none of files on the bucket contain any sensitive information.
Again, it's always good to check the scope, and keep in mind when reporting issues of this nature, they may get rejected if they fall into one of the above categories.
Asset Identification
To complement our previous methods, we can also use other asset identification tools such as Censys, Shodan, or archive.org to expand our attack surface.
Censys.io
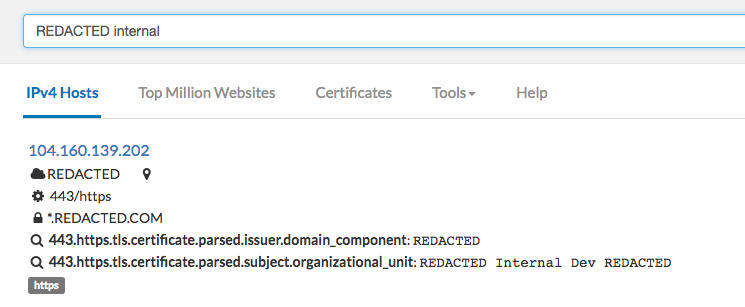
Censys does a great job of scanning IP addresses and gathering information from a set of different ports. Censys could help us find more internal tools and assets by analyzing the SSL certificate belonging to that property. There are different methods and syntaxes to discover content using censys (https://censys.io/overview), but I personally just like to look at a target based on their SSL certs. For example, using the string `443.https.tls.certificate.parsed.extensions.subject_alt_name.dns_names:Yahoo.com` allows us to pull any subdomains/properties that point to Yahoo.com.
We can also tweak our searches on Censys just like any other tools. Creativity is a key asset while doing recon. There have been numerous times where I have searched censys for random patterns such as: “hackme.tld” + internal (or other keywords) that has resulted in finding unique properties that never showed up on my previous searches.
Shodan.io
Shodan is similar to censys, except Shodan scans every IP address, finds any open ports on that IP address, and generates a ton of data and allows users to filter them by location, organization (owning that IP address), open ports, products (apache, tomcat, nginx, etc.), hostname, and more.
That said, we can search for “hostname:hackme.tld org:hackme ports:15672” if we wanted to look for any RabbitMQ instances using a default port on hackme.tld. We can also change the ports option to “product” if we wanted to query for a specific product such as tomcat: “hostname:hackme.tld org:hackme product:tomcat”
You can learn more about Shodan by reading the “Complete Guide to Shodan” written by Shodan’s founder, John Matherly.
Archive.org
Archive.org is another great resource to find old robots.txt files that may contain old endpoints and other sensitive information, find older versions of the site in order to analyze the source and gather more information, and find other old and forgotten subdomains and dev environments. We can do all of this by just visiting Archive.org, searching for our target, picking an older date (maybe from a year or two ago), and clicking around the website.
This could also be automated (and it has been). Using waybackurl.py and waybackrobots.txt, we can find all the information above by running one of the scripts and waiting for the results.
Archive.org is also a great place to find older javascript files that may have still be available to read from. Using this method, we can find more outdated functionalities and endpoints.
After gathering a list of old and new javascript files, we can create a full list of all the endpoints mentioned in those javascript files using JSParser:
Conclusion
The recon process isn’t just about running a set of available tools to find properties. It’s more about getting to know our target first, using those set of tools and combining them with different methods, and using our own creativity in order to find more results. This blog post doesn’t cover every possible way to do a proper recon on a target, however combining the methods above, adding our own thought process, and coming up with more creative methods should be a great place to start.
Happy hacking!
Ben Sadeghipour (@nahamsec)
HackerOne is the #1 hacker-powered security platform, helping organizations find and fix critical vulnerabilities before they can be criminally exploited. As the contemporary alternative to traditional penetration testing, our bug bounty program solutions encompass vulnerability assessment, crowdsourced testing and responsible disclosure management. Discover more about our security testing solutions or Contact Us today.