Strengthen AI safety, security, and trust before you ship
Expose exploit paths across prompts, retrieval pipelines, and agent workflows through human-led, agent-driven adversarial testing.

HackerOne Agentic Prompt Injection Testing
Every H1 AI Red Teaming engagement includes agent-driven testing to validate prompt injection exploitability across retrieval pipelines, tool permissions, and agent workflows. AI agents scale attack paths while human researchers provide judgment and creativity.
The result: provable exploit paths your teams can independently verify, prioritize, and remediate.







Define scope & risk priorities
Identify which AI models, agents, and tool integrations are in scope and establish key risk and safety priorities.
- Identify the AI systems and trust boundaries that are vulnerable to adversarial manipulation.
- Focus on risks such as prompt injection, context poisoning, tool misuse, and data exfiltration, aligned with the OWASP Top 10 for LLMs and Agentic Applications.
- Align the testing scope with your organization's AI risk management strategy.

Design a tailored threat model
Create a threat model and an adversarial test plan aligned with your AI risk priorities.
- Conduct threat modeling across prompts, retrieval layers, tool permissions, and agent workflows.
- Execute structured, multi-turn adversarial scenarios using agent-driven testing under realistic conditions.
- Cover injection chaining, boundary failures, and cross-component abuse across security and safety.

Centralize reporting and remediation
Receive validated findings and reproducible attack traces in the HackerOne Platform.
- Capture confirmed exploit paths with full multi-turn traces and prioritized recommendations.
- Auto-map findings to OWASP LLM Top 10, CWE, MITRE ATLAS, NIST AI RMF, and EU AI Act.
- Track, retest, and validate remediation for measurable AI risk reduction.
Frequently asked questions
AI red teaming is adversarial testing built for AI systems, models, agents, and their integrations. Unlike automated tools or traditional tests, it uses vetted researchers to simulate real-world exploits like jailbreaks, prompt injections, cross-tenant data leakage, and unsafe outputs. Delivered through HackerOne’s AI-augmented platform, each exploit demonstration is paired with actionable fixes so you can remediate quickly and prevent repeat exposure.
Three drivers dominate enterprise AI conversations:
- Compliance deadlines: Reports can be mapped to OWASP, Gartner Trust, Security, and Risk Management (TRiSM) framework, NIST AI RMF, SOC 2, ISO 42001, HITRUST, and GDPR frameworks. This gives enterprises audit-ready documentation that demonstrates AI systems have been tested against recognized security and governance standards, helping teams meet certification and regulatory deadlines with confidence.
- Data isolation concerns: AI red teaming validates that customers can only access authorized data and prevents cross-account leakage. This addresses one of the most common enterprise risks in multi-tenant AI deployments, where a single flaw could expose sensitive data across accounts.
- Product launch timelines: Testing can be scheduled in a week to align with freezes or go-live deadlines, ensuring risk doesn’t block release. This rapid cycle gives product and security teams confidence that AI features can ship on time without introducing untested vulnerabilities.
AI red teaming provides measurable benchmarks: top vulnerabilities by category (e.g., jailbreak success rates, cross-tenant exfiltration attempts, unsafe outputs) and the percentage mitigated across engagements. Using Return on Mitigation (RoM), customers demonstrate how fixes reduce systemic AI risks and prevent compliance failures, supporting both security and business timelines.
HackerOne has already tested 1,700+ AI assets across customer scopes, showing how quickly adoption and security needs are scaling. From this aggregated HackerOne data:
- Cross-tenant data leakage is the highest customer concern, found in nearly all enterprise tests
- Prompt injection and jailbreak exploits that bypass safety filters
- Misaligned outputs, such as recommending competitor products or issuing refunds incorrectly
- Unsafe or biased content that creates compliance and reputational risk
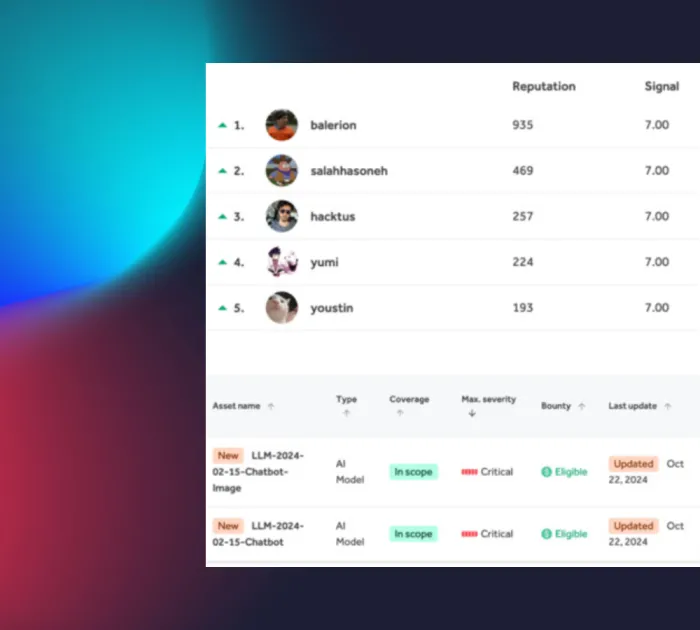
All AI red teaming is performed by vetted AI security researchers with proven expertise in adversarial Machine Learning (ML), application security, and AI deployments. HackerOne offers one of the largest AI-focused researcher communities, with a public leaderboard showing reputation, impact, and accuracy. Today, more than 750 AI-focused researchers actively contribute to engagements for frontier labs and technology-forward enterprises, including Anthropic, Snap, and Adobe.
Results include exploit details, remediation guidance, and centralized, audit-ready reporting. Depending on your objectives, your final report can be aligned to OWASP Top 10 for LLMs, Gartner Trust, Security, and Risk Management (TRiSM) framework, NIST AI RMF, SOC 2, ISO 42001, HITRUST, and GDPR. This ensures your audit trail covers both AI safety risks (harmful or biased outputs) and AI security risks (prompt injection, data poisoning, or exfiltration).
Findings are classified with Hai, HackerOne’s AI security agent, and reviewed in real time with Solutions Architect (SA) support. Reports include exploit details, mapped compliance risks, and remediation guidance, creating audit-ready deliverables for security and governance teams.
Every engagement is paired with an SA who ensures testing is scoped correctly, aligned to your risk profile, and focused on business priorities. SAs translate researcher findings into actionable remediation plans and coordinate throughout the lifecycle, making results easier to deliver, fix, and report against compliance requirements.
Yes. AIRT runs as 15 or 30-day engagements with a defined threat model and risk criteria and can be launched in about one week. This rapid deployment makes it easy to validate defenses before product freezes, go-live deadlines, or regulatory milestones.
- AI-specialized talent: 750+ AI-focused researchers skilled in prompt hacking, adversarial ML, and AI safety.
- Dedicated SA support: Solutions Architects guide threat modeling, scoping, and remediation planning.
- Exploit + fix focus: Every finding includes proof of exploit and a path to remediation.
- Data isolation validation: Unique coverage for cross-tenant leakage, customers’ #1 concern.
- Rapid deployment: A week's startup to match release cycles.
- Trusted by frontier leaders: HackerOne works directly with frontier labs like Anthropic and IBM and their foundational models (Claude, Granite).