Some CISOs Feel Prepared for AI, Some Don’t: Here’s the Difference

AI moved from “we should explore this” to “this is a core part of our business” in record time. That's exciting, but it's also one of the fastest ways to accidentally expand your organization’s attack surface, especially once AI systems start retrieving internal data, calling tools, chaining actions, or making key decisions. That’s why continuous security testing is becoming the default operating model for teams deploying AI at scale.
Most hands-on security practitioners will tell you that AI adoption is fast outpacing security coverage, and this sentiment was backed by HackerOne’s latest enterprise research. In a survey of 303 security leaders (in January to February 2026), almost every organization reported operating more AI or ML systems than a year ago, but fewer reported formally testing most of those systems.
In the same research, a clear maturity signal emerges: the teams that feel well-resourced for AI security skew towards breadth. They are not betting on a single control, a single scan, or a single red team exercise. Instead, they build continuity by combining multiple distinct methods, each covering different blind spots, and each feeding the next loop of validation and remediation.
What follows is a practical breakdown of why the “seven method” approach works, what each method is best at catching, and how to stitch them together into a continuous security program that can keep pace with AI at scale.
AI Adoption Is Scaling Faster Than Security Coverage
As AI systems proliferate, continuous security testing is the only way to keep coverage aligned with what’s actually in production. In HackerOne’s research, 94% of organizations reported adding AI or ML systems in the past year, but only 66% said that most of their AI or ML systems undergo formal security testing.
That gap gets more dangerous when you add two more details from the same study.
- First, only 55% of security leaders said unsanctioned AI usage is fully tracked, 33% described it as only partially tracked and 10% said it is tracked informally. Put plainly: a meaningful slice of AI usage is not properly monitored, secured or even known about.
- Second, the “AI footprint” most enterprises are dealing with is not one chatbot tucked away in marketing. In production, respondents reported widespread use of agentic and embedded AI patterns: AI agents (78%), GenAI code assistants (72%), embedded AI in SaaS tools (66%), and autonomous workflows (55%).
Each of these patterns tends to increase the number of integrations, permissions, data paths, and tool calls you must reason about, which is exactly where AI security gets difficult. When AI becomes a layer inside many workflows, it becomes a multiplier for how many ways a system can be probed, steered, or abused. And that is the root reason security programs are moving from periodic testing to continuous validation. More on that later.
Real Attacks Are Already Landing
A lot of AI security discussions are still being framed as hypothetical, but the data shows that these attacks are already taking place.
In the survey, 84% of organizations reported experiencing AI-related attacks or vulnerabilities in the past 12 months. Even more telling is where those attacks show up. The most commonly reported AI-related attack types span multiple system layers: infrastructure weaknesses like insecure APIs, unauthorized access, and function or agent abuse (51%), model behavior failures like hallucinations or harmful and unsafe outputs (46%), and prompt and interaction attacks like prompt injection, jailbreaks, and guardrail bypasses (40%).
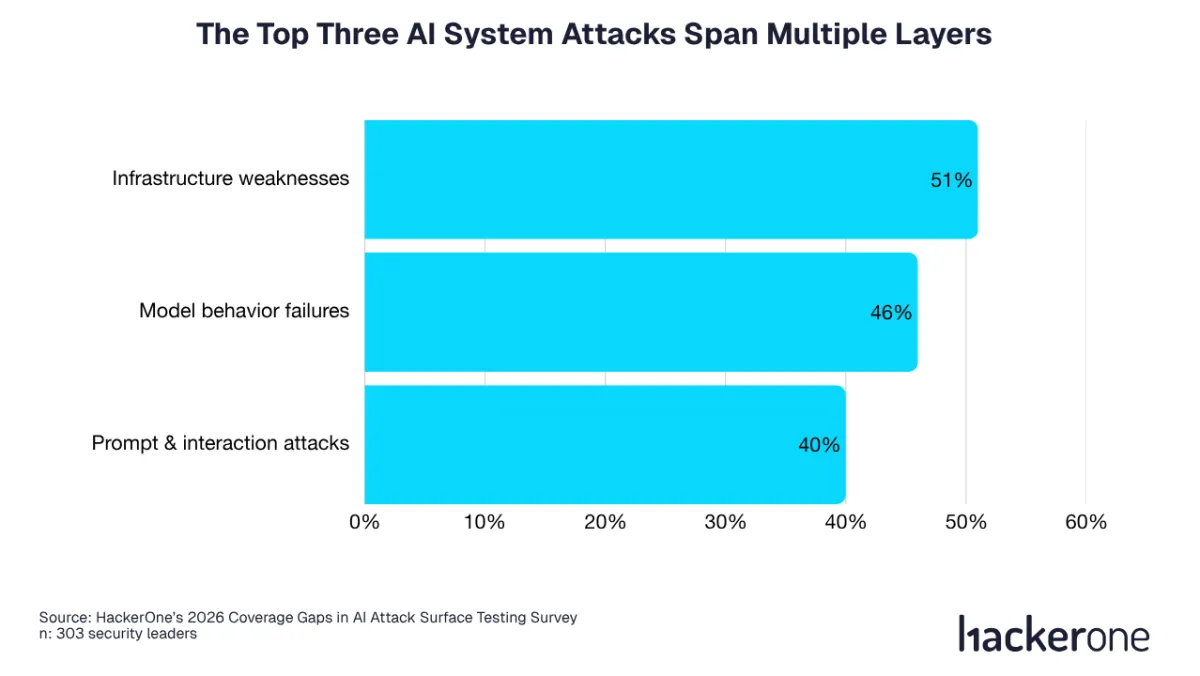
This is the clearest argument against relying on a single testing technique, and moving toward layered, continuous security testing. If your risk surface includes both “classic” security failures (like API auth issues) and AI-specific failures (like unexpected tool execution paths triggered by prompt injection), then your testing needs to cover both deterministic code paths and non-deterministic behavioral paths.
The cost signal in the research is equally hard to ignore. Among organizations that experienced AI-related attacks or vulnerabilities, about 72% reported at least $1 million in total financial impact over the last 12 months.
HackerOne’s analysis also reports a median cost of about $803K per attack, underscoring that “AI incidents” are not a small inconvenience, they are events that blow out budgets and disrupt business operations.
The most actionable (and sobering) insight is how risk scales with AI itself. The research highlights a directional pattern: as organizations move from a small AI footprint (around two AI systems) to a larger footprint (around eight to ten AI systems), they report materially more attacks and materially higher costs. The same pattern shows up even as organizations increase their number of testing methods, which is an important reminder that scale forces you to professionalize and operationalize, not just “add a test”.
This is also the context behind another striking estimate in the summary: adding each new AI or ML system is associated with roughly $300K in additional risk, on average. Every new AI system should come with a repeatable, continuous security motion, not a one-off pre-launch checkbox.
Continuous AI Security Is Not a Slogan
“Continuous security” is such a common phrase now, but the concept is stronger than ever if you can define it in more pragmatic operational terms. In practice, continuous security testing means a repeatable loop of discovery, validation, prioritization, and remediation that stays live as models, prompts, tools, and permissions change.
The recommended path forward is described as continuous security across the AI lifecycle: continuously discovering new and evolving exposures, validating what is real and exploitable, prioritizing based on impact, and driving measurable remediation.
If you want a framework for the same idea, HackerOne points to Continuous Threat Exposure Management (CTEM). CTEM existed as a concept before AI was popularized, but the concepts are still sound. AI tooling just needs to be added to the attack surface that is being managed. If you aren't familiar, CTEM is a continuous loop that discovers exposures, assesses exploitability, prioritizes by business impact, validates through real-world simulation, and remediates. The key difference compared to traditional vulnerability management is that CTEM is designed to stay live as systems change. It tests continuously.
This matters specifically for AI because AI systems are not static. Prompts evolve, guardrails get tuned, tools get added, agent permissions expand, models get swapped. In other words, the attack surface changes at the same cadence as product iteration, sometimes faster.
So the question is not “should we test?” The question is “how do we create a continuous testing cycle that stays trustworthy as the system changes?”
That is exactly why the “seven method” pattern is so useful. Each method produces a different type of security signal. Some are best at catching known issues early. Some are best at surfacing emergent behavior pre-release. Some exist to constrain damage at runtime. Some exist to find the weird edge cases you only discover once real attackers and real users start poking at your system.

The Seven Methods and What Each One Catches
HackerOne’s survey asked security leaders which AI security testing methods they currently use, and the answers are clear. Here they are, along with the percentage of security leaders that picked them.
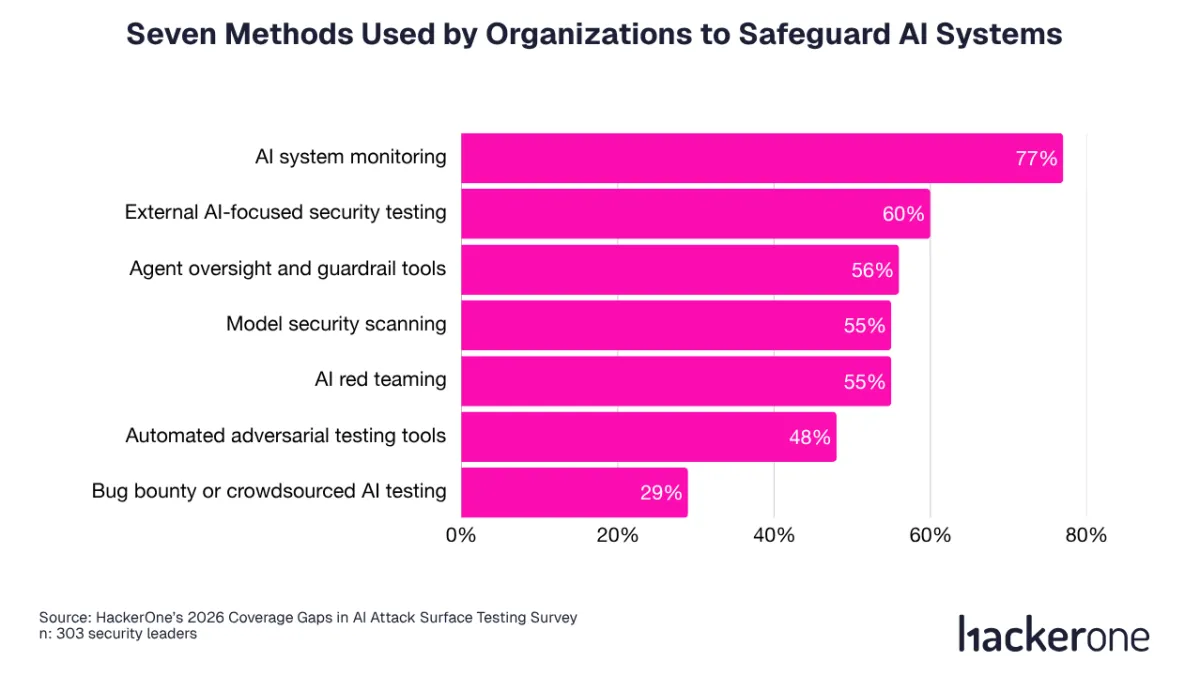
Those percentages are interesting, but what is more useful is what these methods do when combined. Together, these seven methods form continuous security testing for AI: different signals, one operating loop.
- AI red teaming is targeted, scenario-driven adversarial testing that simulates real-world attacker behavior against models, agents, or pipelines. It is designed to uncover failure modes that do not show up in normal evaluation, including prompt injection paths, jailbreaks, tool misuse, and multi-step exploit chains across connected systems.
- Automated adversarial testing tools give you breadth and repeatability. They are how you scale adversarial probing across many prompts, languages, policies, and attack patterns, and they are especially valuable for regression testing after changes to prompts, models, tools, or policies.
- Model security scanning is the “known weakness detection” layer for your ML stack: configurations, dependencies, containers, endpoints, and unsafe defaults. It is fast, systematic, and good at preventing avoidable basics from shipping, particularly in the complex dependency chains that modern AI applications tend to inherit.
- Agent oversight and guardrail tools exist because agents can take actions. Oversight constrains permissions, tool access, and action boundaries, reducing blast radius when the model is manipulated, overconfident, or simply wrong. In a world where 78% of organizations report AI agents in production, guardrails are quickly becoming table stakes, but they are not a replacement for testing. They are your runtime seatbelt.
- AI system monitoring is your real-world safety net: monitoring prompts, tool calls, outputs, and anomalies so you can detect abuse patterns and drift after deployment. In a CTEM-style operating model, monitoring is part of the continuous feedback loop that tells you where to focus the next round of validation and hardening.
- External AI-focused security testing provides independent validation and specialized expertise. It is especially valuable for high-stakes launches, regulated contexts, and scenario coverage you do not have time to build internally. In HackerOne’s survey, 54% of security leaders said they plan to begin using external AI-focused security testing over the next 12 months, which is a strong indicator that many organizations see external validation as the fastest way to close the AI security gap.
- Bug bounty or crowdsourced AI testing brings scale, diversity, and long-tail creativity over time. A researcher community will find edge cases and exploit chains that smaller, time-boxed teams miss, particularly as attacker tactics evolve. This is one reason bug bounty programs are often framed as continuous researcher-led testing rather than a single exercise.
To a security leader who is already overwhelmed by the onslaught of AI, this list is going to feel like “a lot”, but that is the point. Each method exists because the others have blind spots. Red teaming is deep but time-boxed. Automated adversarial testing is broad but not always context-aware. Scanning is fast but focuses on known issues. Guardrails help at runtime but can be bypassed or misconfigured. Monitoring tells you what is happening, not necessarily how to fix it. External testing adds independence, not continuity. Bug bounty adds continuity and diversity, but it needs clear scope, triage, and remediation workflows to convert reports into risk reduction.
Combining all seven provides the best coverage.
How to Stitch Seven Methods Into One Continuous Program
The biggest mistake I see teams make is treating these methods as separate procurement decisions. The better mental model is to treat them as a single system, where each method creates signal, and that signal flows into a single source for prioritization and remediation.
A practical way to visualize the “continuous security testing” program is as three connected loops: pre-release prevention, pre-release adversarial validation, and post-release continuous discovery.
- In the prevention loop, model and stack scanning catches preventable issues early, before they become incidents. It is your baseline hygiene layer.
- In the adversarial validation loop, automated adversarial testing and AI red teaming pressure-test behavior and orchestration, with external testing providing independent scrutiny when the stakes are high or internal capacity is stretched. This is where you test the parts of AI that do not have fixed execution paths, and where you learn what “real exploitation” looks like in your specific architecture.
- In the post-release loop, monitoring plus crowdsourced testing create the continuous pressure you cannot simulate fully in a lab. Monitoring helps you spot emergent patterns and drift. Bug bounty helps you learn what creative attackers can do over time, across languages, threat models, and unexpected interaction patterns.
What makes this “one program” rather than “seven activities” is how each activity provides feedback to the others. A monitoring alert should become a new red team scenario. A bug bounty report should become a regression test in your automated adversarial suite. A red team exploit chain should become a guardrail improvement plus a detection. A scanning finding should become a build-time gate. That is the continuous motion: every signal becomes a test, a control improvement, and ideally a measurable reduction in exploitable exposure.
A Note on Ownership
A slightly counterintuitive insight from the research is that ownership is necessary but not sufficient. The study reports broad formal ownership for offensive security of AI systems, often involving a mix of internal security teams, internal AI or MLOps teams, and external providers. Yet attacks remain widespread and costly. In other words, having “a team responsible” does not automatically translate into continuous, end-to-end security coverage. The operational loop is what converts ownership into outcomes.
If you are looking for a pragmatic way to sequence this, do not try to “do everything at once” in a vague way. Instead, align the sequence to what you are actually deploying. For example, if your AI deployments are mostly embedded features in existing SaaS workflows, start by treating the AI layer as an extension of application security: scan the stack, pentest the end-to-end app and integrations, validate prompt and interaction pathways, and make sure monitoring is instrumented in production.
For agentic systems, you might instead prioritize guardrails, tool boundary validation, and red team scenarios that reflect what the agent can actually do. Keep in mind that the more autonomy you ship, the more your security program needs to validate behavior, rather than just static code.
What CISOs Should Take Away From the Data
Let’s bring it back to the simplest leadership question: what should you do differently on Monday? The survey data suggests three moves that are both practical and hard to argue with.
- First, close the coverage gap. If AI adoption growth outpaces formal testing, you're effectively leaving a huge gap in the attack surface.
- Second, treat AI security as multi-layer. The most commonly reported AI attacks and vulnerabilities spanned infrastructure weaknesses, model behavior failures, and prompt and interaction attacks. There's no single tool or process that will fill the gap. There needs to be new multi-layered processes to effectively handle the change.
- Third, operationalize continuity. Whether you call it continuous security across the AI lifecycle or CTEM, security must become a constant loop of discovery, validation, prioritization, and remediation.
On Monday, start by defining what continuous security testing means for your AI footprint, then assign ownership for the loop, not just the tools.
About the Author