Why Real-World Testing Makes Agentic Pentesting Smarter Over Time

Security is not a stationary environment. Vulnerabilities get remediated, applications change, new attack paths emerge, and most importantly, static test data ages quickly. If AI is going to deliver durable security value, it cannot be measured solely by synthetic benchmarks; it must improve through real-world exposure, research validation, and rapid iteration.
That is the approach behind Agentic Pentest as a Service (PTaaS) at HackerOne, where AI agents autonomously plan, execute, and adapt multi-step attack sequences rather than running predefined scan rules.
Benchmarks Protect Stability
We start where every serious engineering effort starts: repeatable evaluation. Industry and custom domain benchmarks are essential for regression detection, stability improvements, controlled capability expansion, and release confidence. In benchmark testing, our systems achieved 88% fix-verified accuracy, more than doubling model-only accuracy while keeping false positives low.
These tests are high-signal, repeatable, and fast to run. They act as a regression harness for the agent, catching capability drift and unintended behavior changes before they ship. But in security, repeatability alone doesn’t always guarantee relevance.
Production Exposure Drives Capability Expansion
Production environments create learning opportunities that benchmarks cannot. This includes unpredictable authentication flows, complex business logic, unique configurations and integrations, and real remediation cycles.
Leading up to the launch of Agentic PTaaS, we ran our offensive security AI agents against over 100 real-world web application targets across industries, including EdTech, financial services, insurance, agriculture, enterprise software, and pharmaceuticals.
This is where capability expands fastest: in the field, against real constraints. Many systems can occasionally get real-world exposure, but far fewer can turn that exposure into a structured, repeatable improvement engine.
A Simple Agent Improvement Framework
We think about agent evaluation across two dimensions: novel learning opportunities (how much the environment reveals new failure modes) and structured feedback frequency (how often validated outcomes translate into product improvements).
Agents improve through exposure to real environments and structured feedback on outcomes. In security, that feedback depends on validated ground truth established through researcher review and operationalized into continuous system improvements.
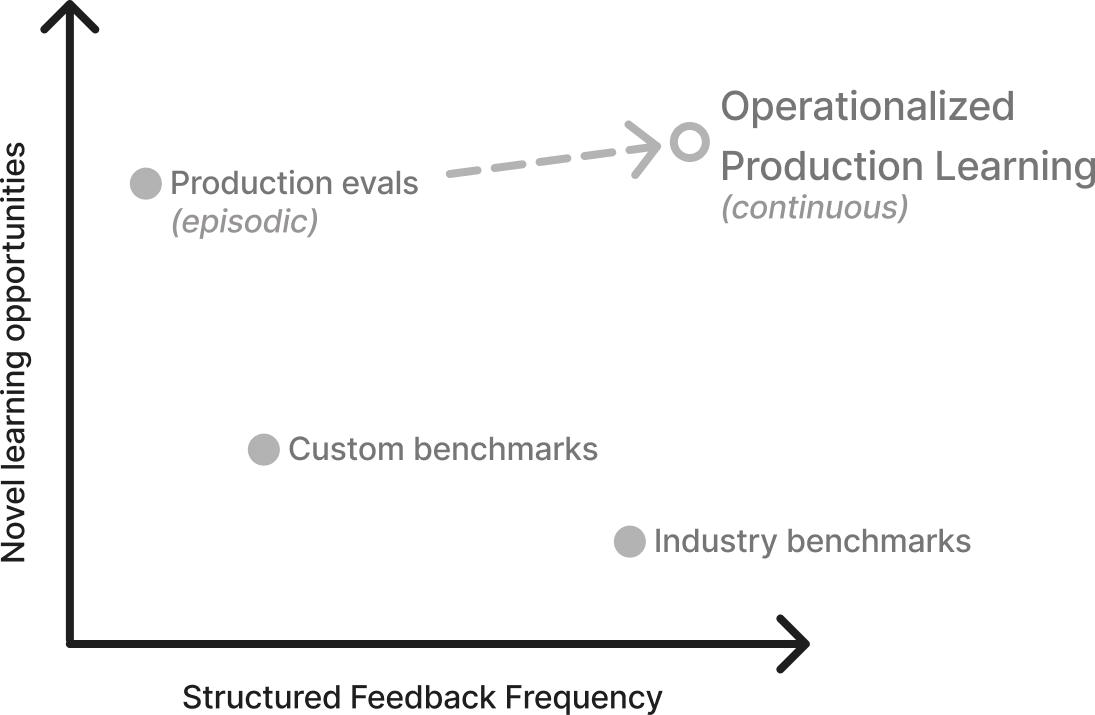
- Benchmarks cluster in the high-structured-feedback, low-novelty region; environments like DVWA or other intentionally vulnerable apps are great for catching regressions and validating known patterns, but they rarely surface new failure modes.
- Production exposure sits in the opposite corner: high-novelty, low-structured feedback frequency. Real applications introduce bespoke authentication flows, complex permission models, and business logic risks, like IDORs that don’t resemble simple lab examples.
- Most organizations operate in one of these two modes: strong benchmark coverage or occasional production testing. The shift is increasing structured feedback in real environments, so learning happens continuously, not just after isolated engagements.
Durable capability growth happens when novel learning opportunities are paired with frequent, structured feedback grounded in researcher-validated outcomes, turning failure modes into repeatable improvements.
Improvement Velocity
Our production engagements served as a forcing function for rapid improvement after the initial runs:
- Customer feedback and observed gaps drove coverage expansion across three new vulnerability classes, including IDOR (CWE-639), stored XSS (CWE-79), and SQL injection (CWE-89).
- Reliability improved as well, including a ~20% reduction in agent crash rate on novel applications across the design partner cohort.
- When findings are remediated, we can re-run agents to validate fixes quickly, giving customers faster confirmation loops.
- Most importantly, the iteration cycle from "observed in production" to "improved in product" was achieved in hours, with engineers and researchers closely connected to the feedback. This gave clear evidence that production engagements should not be used for one-time tuning exercises, but for a repeatable operating model.
Reality-Grade Stability
Production engagement feedback loops focus on validated capability and stability improvements in dynamic environments that serve real-world purposes, rather than on training on customer business logic or application data. We learn from outcomes and patterns, including coverage gaps, failure modes, and validation results, while maintaining strict customer confidentiality and data boundaries.
The Promise of Agentic Security Goes Beyond a Single Release
For agentic security to deliver lasting value, it needs environments diverse enough to surface real failure modes, the operational ability to run safely at scale, and validation workflows that turn every finding into feedback that makes the system better.
HackerOne’s advantage comes from the feedback system around the agent: real-world environments, expert researcher validation, and tight engineering loops that translate production outcomes into safer, faster capability gains. That combination is much harder to replicate than model performance alone. That is exactly where HackerOne's history becomes an advantage:
- Our experience across thousands of enterprise pentests provides broad exposure to the environments, workflows, and edge cases that benchmarks alone cannot capture.
- Our researcher network and design partners help validate findings, surface meaningful gaps, and ensure improvements are grounded in the standards enterprise teams expect.
- The best part, our customers are already seeing this play out in production.
As adoption grows, we expect the feedback loop to accelerate, with each new engagement driving broader coverage, stronger reliability, and deeper capability over time.
See how Agentic PTaaS turns real-world testing into faster, validated improvements
About the Author



