Finding Fast, Fixing Slow: The Crisis of Asymmetric Remediation

Over the past eighteen months, AI models have gone from barely completing beginner-level cybersecurity tasks to AI vulnerability discovery at a pace that includes autonomously finding and exploiting flaws in open source and other production software.
The progression has been fast enough that each milestone felt like a ceiling until the next model broke through it.
What Changed in AI Vulnerability Discovery Since 2024
The inflection point was visible by mid-2024, when DARPA's AI Cyber Challenge (AIxCC) put autonomous cyber reasoning systems against synthetic vulnerabilities in critical open-source projects like the Linux kernel, Nginx, and SQLite.
At the DEFCON 32 semifinals, the best AI systems identified 37% of planted vulnerabilities and patched 25%. One year later at DEFCON 33, those numbers jumped to 86% identification and 68% patching. The winning systems also found 18 real-world vulnerabilities that weren't part of the competition, at an average cost of $152 per task. All seven finalist systems were released as open source.
Meanwhile, the foundation models themselves were climbing a separate curve. The UK AI Safety Institute has tracked cyber capabilities across model generations since 2023, and the trajectory is striking. Early models like GPT-4o could handle only basic capture-the-flag tasks. Opus 4.5 and GPT-5.1 pushed into intermediate territory. By the time GPT-5.4 and Opus 4.6 arrived, they were solving practitioner-level challenges and, in Opus 4.6's case, finding hundreds of zero-day vulnerabilities in production open-source codebases during Anthropic's internal testing. Expert-level tasks that no model could complete before April 2025 were suddenly within reach.
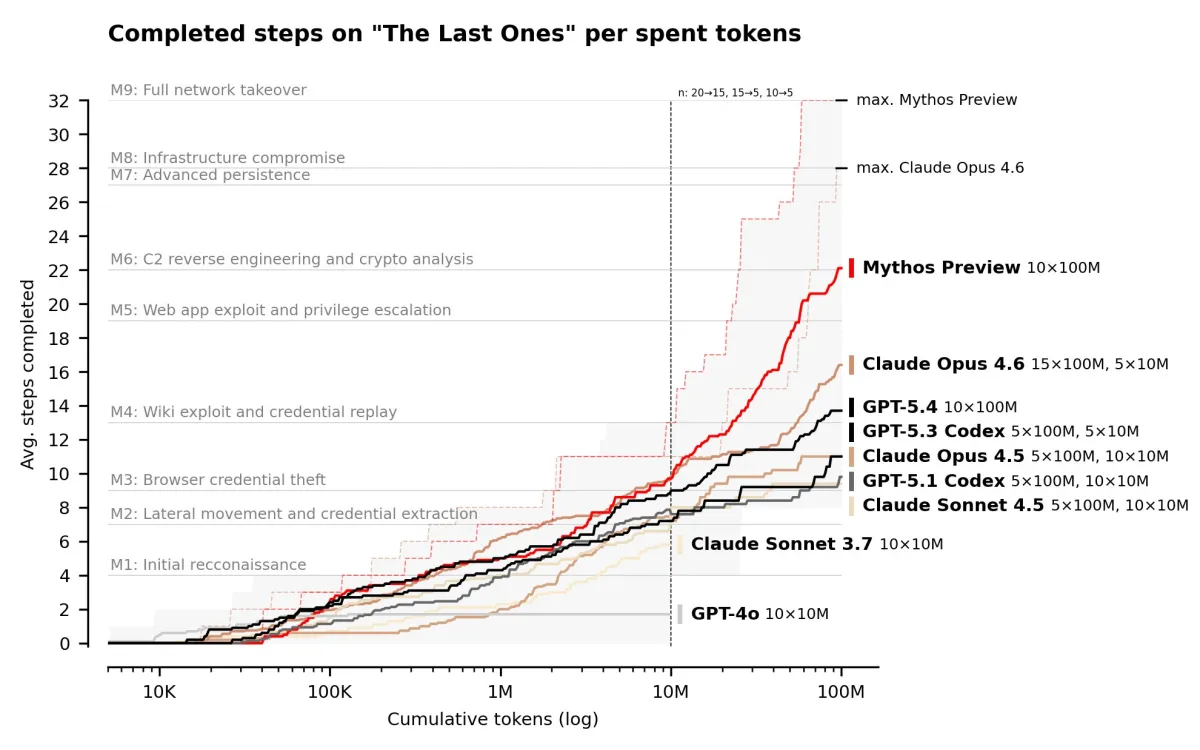
Then, Mythos Preview was announced in April 2026, and the curve bent again. On the AISI's expert-level evaluations, Mythos succeeds 73% of the time. On a 32-step corporate network attack simulation (spanning reconnaissance through full network takeover), it completes stages that previous models couldn't reach at any token budget. Anthropic has chosen not to release the model publicly, instead restricting access to a consortium of partners through Project Glasswing.
Others are close too. OpenAI announced Aardvark, a GPT-5-powered autonomous security agent, in late 2025. Google and others are building similar capabilities into their platforms.
As these capabilities proliferate, and as open-weight models catch up, AI-driven vulnerability discovery won't be limited to frontier labs running expensive internal evaluations. It will become cheap, available, and routine. That changes the math on a fundamental question that we will explore via this post.
How Much Risk Is Still Hiding in Your Codebase?
A decade ago, Dan Geer borrowed a technique from wildlife biology to ask a deceptively simple question about software security: how many vulnerabilities are hiding in our code? His approach was capture-recapture, the same method biologists use to estimate frog populations in a pond. It offered a statistical lens on what security teams had been discussing for years.
The method works like this. Catch 41 frogs, mark them, release them. A week later, catch 62 frogs and count how many are marked. If 6 are banded, the Lincoln Index gives us:
N = (41 × 62) / 6 = 424 frogs

Replace frogs with vulnerabilities and pond with a production codebase, and we have the essential question Bruce Schneier posed around the same time in an article in The Atlantic: are vulnerabilities in software dense or sparse?
If vulnerabilities are sparse, say 6 total, then finding and patching one is a 15% improvement. Feels worth it. But if they're dense, 6,000 say, then patching one is noise. We've spent real money to move a needle nobody can see.
For most of the history of software security, we operated as though vulnerabilities were sparse. Not because we had evidence, but because our tools and methods could only find them slowly. Bug bounty programs, manual pentests, static analysis, they all surfaced vulnerabilities at a pace that made the problem feel manageable. The discovery rate sets the perceived density.
What AI Is Teaching Us About Vulnerability Density
In early 2026, Anthropic partnered with Mozilla and pointed to Claude Opus 4.6 at the Firefox codebase. Firefox is a well audited open-source codebase. Tens of millions of users, decades of security review, a mature bug bounty program. In two weeks, scanning roughly 6,000 C++ files, it filed 112 unique bug reports. Mozilla confirmed 22 as CVEs, 14 of them high-severity. Anthropic’s blog says that's almost a fifth of all high-severity Firefox vulnerabilities that were remediated in 2025.
If we apply this to what it means through Geer's removal-capture lens. In removal-capture, we estimate the original population N0 from two successive hunts of equal effort, where each find is removed from the pool:
N₀ = n₁² / (n₁ − n₂)
Imagine two independent pentest teams hitting the same target in sequence. Team A finds 80 vulnerabilities, Team B (working the now-reduced pool) finds 60. The estimate:
N₀ = 80² / (80 − 60) = 6,400 / 20 = 320 vulnerabilities
Each successive hunt catches fewer, suggesting the population is finite and being drawn down. This is what sparse looks like through the formula. The discovered count drops with each catch because there are fewer left to catch.
Now hypothetically, if we run the same exercise with an AI autonomous discovery system. First pass: 800 findings. Second pass of equal effort: 720. The catch barely drops, because the pool is enormous relative to what's being removed:
N₀ = 800² / (800 − 720) = 640,000 / 80 = 8,000 vulnerabilities
The estimated population jumps by 25x because a more powerful and new approach to discovery reveals a denominator that was always there. The previous discovery approaches weren't sampling a small pond. They were skimming the surface of a deep one, and the sparse drop-off between catches was an artifact of their limited reach, not the population's actual size.
Density also compounds along attack paths. If the probability of a usable vulnerability is high at each node between an attacker's entry point and their objective, the overall probability of a successful chain stays high regardless of how many steps are involved. Sparse environments gave defenders safety in depth. Dense environments turn depth into exposure.
This is what the Mythos data shows at scale. Anthropic ran both Opus 4.6 and Mythos against the same Firefox 147 JavaScript engine vulnerabilities. Opus managed to turn those bugs into working exploits exactly twice out of several hundred attempts. Mythos produced 181 working exploits, plus register control on 29 more. Same bugs. Radically different capture capability.
As per the latest Mythos blog, the jump wasn't limited to Firefox. Across roughly a thousand open-source repositories in the OSS-Fuzz corpus (about 7,000 entry points), Opus 4.6 produced around 275 crashes at the two lowest severity tiers and hit tier 3 exactly once. Mythos hit 595 crashes at those same tiers, added a handful at tiers 3 and 4, and achieved full control-flow hijack on ten separate, fully patched targets.
It is probably safe to say that the vulnerabilities were always dense. We just didn't have the capture rate to see it. The measurements were restricted by our own limitations, not the software's actual attack surface.
Finding Fast, Fixing Slow: The Remediation Bottleneck
The current discovery capability has jumped by an order of magnitude, but remediation capability hasn’t yet.
Most organizations still patch vulnerabilities one at a time. A finding gets triaged, assigned, queued behind the sprint, reviewed, tested, deployed. This cadence was designed for a world where we found 1 critical exploitable vulnerability a week maybe, not 1 an hour.
If we're finding vulnerabilities at dense-world rates but fixing them at sparse-world rates, we're falling behind on every cycle. The backlog doesn't just grow, it compounds. Each unfixed vulnerability is a window that stays open while attackers with AI powered capabilities are scanning with the same tools that found it.
Schneier identifies this gap in his recent essay on cybersecurity in the age of instant software. He notes that even when defensive AI can find flaws, patching requires holistic understanding, testing, and organizational coordination that can't be automated as easily.
From Discovery to Risk Reduction: What Has to Change Now
The old framing was to find vulnerabilities, patch them, repeat. That worked when both discovery and the underlying vulnerability population appeared sparse. But Mythos and similar models are moving the frontier. We're now staring at a dense vulnerability landscape with remediation infrastructure built for a sparse one.
Fixing this one-by-one won't work. When we're pulling hundreds of vulnerabilities out of a pond that holds tens of thousands, we don't need a better net. We need to drain the pond.
- Organizational redesign. One of the constraints in vulnerability management is the human handoffs between different teams from discovery to remediation. In a modern, data-rich environment, relying on sparse-era processes, like tickets languishing in queues or findings needing multiple back and forth between teams creates a bottleneck. Organizations will need to minimize human transfer points, collapsing the distance between a vulnerability's discovery and its fix into a single, seamless loop.
- Feedback loops that improve design. If the same class of vulnerability keeps showing up (and at dense rates, it will), we can't patch our way out. We have to feed discovery data back into how software gets designed and built. Treat vulnerability clusters as design defects, not individual bugs.
- High-fidelity validation as the required condition. In complex environments, the challenge of false positives becomes severe. Not every discovery represents an exploitable vulnerability in the unique context of its deployment. Organizations that expend effort chasing non-exploitable findings and theoretical risks will be overwhelmed. The focus must be on validated, exploitable risk. This necessitates the kind of triage and validation that uses the same capabilities of AI at scale and combines with human judgment wherever required to accurately distinguish the critical 80 risks from the distracting 800 non-critical alerts.
The Future of AI Vulnerability Discovery and Security Operations
Geer's 2015 column invited us to explore the potential for those who test or closely observe testing to find a greater concentration of vulnerabilities.
A decade later, it might be safe to say, vulnerabilities are dense. The core issue is no longer the sheer number of vulnerabilities, but whether our organizations, processes, and economic models can adapt to the speed this new reality demands.
The Mythos preview is significant because it forced the industry to confront a fundamental assumption that vulnerabilities are scarce enough to manage individually was probably wrong. The next challenge is to retool our approach for managing them at scale.
Make high-fidelity validation your speed advantage with h1 Validation
About the Authors